Antoine Beaupr : (Re)introducing screentest
I have accidentally rewritten screentest, an old
X11/GTK2 program that I was previously using to, well, test
screens.
Screentest is dead
It was removed from Debian in May 2023 but had already missed two
releases (Debian 11 "bullseye" and 12 "bookworm") due to release
critical bugs. The stated reason for removal was:
Screentest is dead
It was removed from Debian in May 2023 but had already missed two
releases (Debian 11 "bullseye" and 12 "bookworm") due to release
critical bugs. The stated reason for removal was:
The package is orphaned and its upstream is no longer developed. It
depends on gtk2, has a low popcon and no reverse dependencies.
So I had little hope to see this program back in Debian. The git
repository shows little activity, the last being two years
ago. Interestingly, I do not quite remember what it was testing, but
I do remember it to find dead pixels, confirm native resolution, and
various pixel-peeping. Here's a screenshot of one of the screentest
screens:
 Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running wayland now, surely there's
something better?
Well, no. Of course not. Someone would know about it and tell me
before I go on a random coding spree in a fit of
procrastination... riiight? At least, the Debconf video team
didn't seem to know of any replacement. They actually suggested I just
"invoke gstreamer directly" and "embrace the joy of shell scripting".
Now, I think it's safe to assume this program is dead and buried, and
anyways I'm running wayland now, surely there's
something better?
Well, no. Of course not. Someone would know about it and tell me
before I go on a random coding spree in a fit of
procrastination... riiight? At least, the Debconf video team
didn't seem to know of any replacement. They actually suggested I just
"invoke gstreamer directly" and "embrace the joy of shell scripting".
Screentest reborn
So, I naively did exactly that and wrote a horrible shell
script. Then I realized the next step was to write an command line
parser and monitor geometry guessing, and thought "NOPE, THIS IS WHERE
THE SHELL STOPS", and rewrote the whole thing in Python.
Now, screentest lives as a ~400-line Python script, half of which is
unit test data and command-line parsing.
Why screentest
Some smarty pants is going to complain and ask why the heck one would
need something like that (and, well, someone already did), so maybe I
can lay down a list of use case:
- testing color output, in broad terms (answering the question of "is
it just me or this project really yellow?")
- testing focus and keystone ("this looks blurry, can you find a nice
sharp frame in that movie to adjust focus?")
- test for native resolution and sharpness ("does this projector
really support 4k for 30$? that sounds like bullcrap")
- looking for dead pixels ("i have a new monitor, i hope it's
intact")
What does screentest do?
Screentest displays a series of "patterns" on screen. The list of
patterns is actually hardcoded in the script, copy-pasted from this
list from the videotestsrc gstreamer plugin, but you can pass
any pattern supported by your gstreamer installation with
--patterns. A list of patterns relevant to your installation is
available with the gst-inspect-1.0 videotestsrc command.
By default, screentest goes through all patterns. Each pattern runs
indefinitely until the you close the window, then the next pattern
starts.
You can restrict to a subset of patterns, for example this would be a
good test for dead pixels:
screentest --patterns black,white,red,green,blue
This would be a good sharpness test:
screentest --patterns pinwheel,spokes,checkers-1,checkers-2,checkers-4,checkers-8
A good generic test is the classic SMPTE color bars and is the
first in the list, but you can run only that test with:
screentest --patterns smpte
(I will mention, by the way, that as a system administrator with
decades of experience, it is nearly impossible to type SMPTE
without first typing SMTP and re-typing it again a few times
before I get it right. I fully expect this post to have numerous
typos.)
Here's an example of the SMPTE pattern from Wikipedia:
 For multi-monitor setups,
For multi-monitor setups, screentest also supports specifying which
output to use as a native resolution, with --output. Failing that,
it will try to look at the outputs and use the first it will
find. If it fails to find anything, you can specify a resolution with
--resolution WIDTHxHEIGHT.
I have tried to make it go full screen by default, but stumbled a bug
in Sway that crashes gst-launch. If your Wayland compositor
supports it, you can possibly enable full screen with --sink
waylandsink fullscreen=true. Otherwise it will create a new window
that you will have to make fullscreen yourself.
For completeness, there's also an --audio flag that will emit the
classic "drone", a sine wave at 440Hz at 40% volume (the audiotestsrc
gstreamer plugin. And there's a --overlay-name option to show
the pattern name, in case you get lost and want to start with one of
them again.
How this works
Most of the work is done by gstreamer. The script merely generates a
pipeline and calls gst-launch to show the output. That both
limits what it can do but also makes it much easier to use than
figuring out gst-launch.
There might be some additional patterns that could be useful, but I
think those are better left to gstreamer. I, for example, am somewhat
nostalgic of the Philips circle pattern that used to play for TV
stations that were off-air in my area. But that, in my opinion, would
be better added to the gstreamer plugin than into a separate thing.
The script shows which command is being ran, so it's a good
introduction to gstreamer pipelines. Advanced users (and the video
team) will possibly not need screentest and will design their own
pipelines with their own tools.
I've previously worked with ffmpeg pipelines (in another such
procrastinated coding spree, video-proxy-magic), and I found
gstreamer more intuitive, even though it might be slightly less
powerful.
In retrospect, I should probably have picked a new name, to avoid
crashing the namespace already used by the project, which is now on
GitHub. Who knows, it might come back to life after this blog
post; it would not be the first time.
For now, the project lives along side the rest of my scripts
collection but if there's sufficient interest, I might move it to
its own git repositories. Comments, feedback, contributions are as
usual welcome. And naturally, if you know something better for this
kind of stuff, I'm happy to learn more about your favorite tool!
So now I have finally found something to test my projector, which will
likely confirm what I've already known all along: that it's kind
of a piece of crap and I need to get a proper one.
Why screentest
Some smarty pants is going to complain and ask why the heck one would
need something like that (and, well, someone already did), so maybe I
can lay down a list of use case:
- testing color output, in broad terms (answering the question of "is
it just me or this project really yellow?")
- testing focus and keystone ("this looks blurry, can you find a nice
sharp frame in that movie to adjust focus?")
- test for native resolution and sharpness ("does this projector
really support 4k for 30$? that sounds like bullcrap")
- looking for dead pixels ("i have a new monitor, i hope it's
intact")
What does screentest do?
Screentest displays a series of "patterns" on screen. The list of
patterns is actually hardcoded in the script, copy-pasted from this
list from the videotestsrc gstreamer plugin, but you can pass
any pattern supported by your gstreamer installation with
--patterns. A list of patterns relevant to your installation is
available with the gst-inspect-1.0 videotestsrc command.
By default, screentest goes through all patterns. Each pattern runs
indefinitely until the you close the window, then the next pattern
starts.
You can restrict to a subset of patterns, for example this would be a
good test for dead pixels:
screentest --patterns black,white,red,green,blue
This would be a good sharpness test:
screentest --patterns pinwheel,spokes,checkers-1,checkers-2,checkers-4,checkers-8
A good generic test is the classic SMPTE color bars and is the
first in the list, but you can run only that test with:
screentest --patterns smpte
(I will mention, by the way, that as a system administrator with
decades of experience, it is nearly impossible to type SMPTE
without first typing SMTP and re-typing it again a few times
before I get it right. I fully expect this post to have numerous
typos.)
Here's an example of the SMPTE pattern from Wikipedia:
For multi-monitor setups, screentest also supports specifying which
output to use as a native resolution, with --output. Failing that,
it will try to look at the outputs and use the first it will
find. If it fails to find anything, you can specify a resolution with
--resolution WIDTHxHEIGHT.
I have tried to make it go full screen by default, but stumbled a bug
in Sway that crashes gst-launch. If your Wayland compositor
supports it, you can possibly enable full screen with --sink
waylandsink fullscreen=true. Otherwise it will create a new window
that you will have to make fullscreen yourself.
For completeness, there's also an --audio flag that will emit the
classic "drone", a sine wave at 440Hz at 40% volume (the audiotestsrc
gstreamer plugin. And there's a --overlay-name option to show
the pattern name, in case you get lost and want to start with one of
them again.
How this works
Most of the work is done by gstreamer. The script merely generates a
pipeline and calls gst-launch to show the output. That both
limits what it can do but also makes it much easier to use than
figuring out gst-launch.
There might be some additional patterns that could be useful, but I
think those are better left to gstreamer. I, for example, am somewhat
nostalgic of the Philips circle pattern that used to play for TV
stations that were off-air in my area. But that, in my opinion, would
be better added to the gstreamer plugin than into a separate thing.
The script shows which command is being ran, so it's a good
introduction to gstreamer pipelines. Advanced users (and the video
team) will possibly not need screentest and will design their own
pipelines with their own tools.
I've previously worked with ffmpeg pipelines (in another such
procrastinated coding spree, video-proxy-magic), and I found
gstreamer more intuitive, even though it might be slightly less
powerful.
In retrospect, I should probably have picked a new name, to avoid
crashing the namespace already used by the project, which is now on
GitHub. Who knows, it might come back to life after this blog
post; it would not be the first time.
For now, the project lives along side the rest of my scripts
collection but if there's sufficient interest, I might move it to
its own git repositories. Comments, feedback, contributions are as
usual welcome. And naturally, if you know something better for this
kind of stuff, I'm happy to learn more about your favorite tool!
So now I have finally found something to test my projector, which will
likely confirm what I've already known all along: that it's kind
of a piece of crap and I need to get a proper one.
--patterns. A list of patterns relevant to your installation is
available with the gst-inspect-1.0 videotestsrc command.
By default, screentest goes through all patterns. Each pattern runs
indefinitely until the you close the window, then the next pattern
starts.
You can restrict to a subset of patterns, for example this would be a
good test for dead pixels:
screentest --patterns black,white,red,green,blue
screentest --patterns pinwheel,spokes,checkers-1,checkers-2,checkers-4,checkers-8
screentest --patterns smpte
(I will mention, by the way, that as a system administrator with decades of experience, it is nearly impossible to type SMPTE without first typing SMTP and re-typing it again a few times before I get it right. I fully expect this post to have numerous typos.)Here's an example of the SMPTE pattern from Wikipedia:
For multi-monitor setups, screentest also supports specifying which
output to use as a native resolution, with --output. Failing that,
it will try to look at the outputs and use the first it will
find. If it fails to find anything, you can specify a resolution with
--resolution WIDTHxHEIGHT.
I have tried to make it go full screen by default, but stumbled a bug
in Sway that crashes gst-launch. If your Wayland compositor
supports it, you can possibly enable full screen with --sink
waylandsink fullscreen=true. Otherwise it will create a new window
that you will have to make fullscreen yourself.
For completeness, there's also an --audio flag that will emit the
classic "drone", a sine wave at 440Hz at 40% volume (the audiotestsrc
gstreamer plugin. And there's a --overlay-name option to show
the pattern name, in case you get lost and want to start with one of
them again.
 Meeting Debian people for having a good time together, for some good hacking,
for learning, for teaching Is always fun and welcome. It brings energy, life
and joy. And this year, due to the six-months-long relocation my family and me
decided to have to Argentina, I was unable to attend the real deal, DebConf23 at
India.
And while I know DebConf is an experience like no other, this year I took part
in two miniDebConfs. One I have already shared in this same blog: I was in
Meeting Debian people for having a good time together, for some good hacking,
for learning, for teaching Is always fun and welcome. It brings energy, life
and joy. And this year, due to the six-months-long relocation my family and me
decided to have to Argentina, I was unable to attend the real deal, DebConf23 at
India.
And while I know DebConf is an experience like no other, this year I took part
in two miniDebConfs. One I have already shared in this same blog: I was in












 Dormitory room in Zostel Ernakulam, Kochi.
Dormitory room in Zostel Ernakulam, Kochi.
 Beds in Zostel Ernakulam, Kochi.
Beds in Zostel Ernakulam, Kochi.
 Onam sadya menu from Brindhavan restaurant.
Onam sadya menu from Brindhavan restaurant.
 Sadya lined up for serving
Sadya lined up for serving
 Sadya thali served on banana leaf.
Sadya thali served on banana leaf.
 We were treated with such views during the Wayanad trip.
We were treated with such views during the Wayanad trip.
 A road in Rippon.
A road in Rippon.
 Entry to Kanthanpara Falls.
Entry to Kanthanpara Falls.
 Kanthanpara Falls.
Kanthanpara Falls.
 A view of Zostel Wayanad.
A view of Zostel Wayanad.
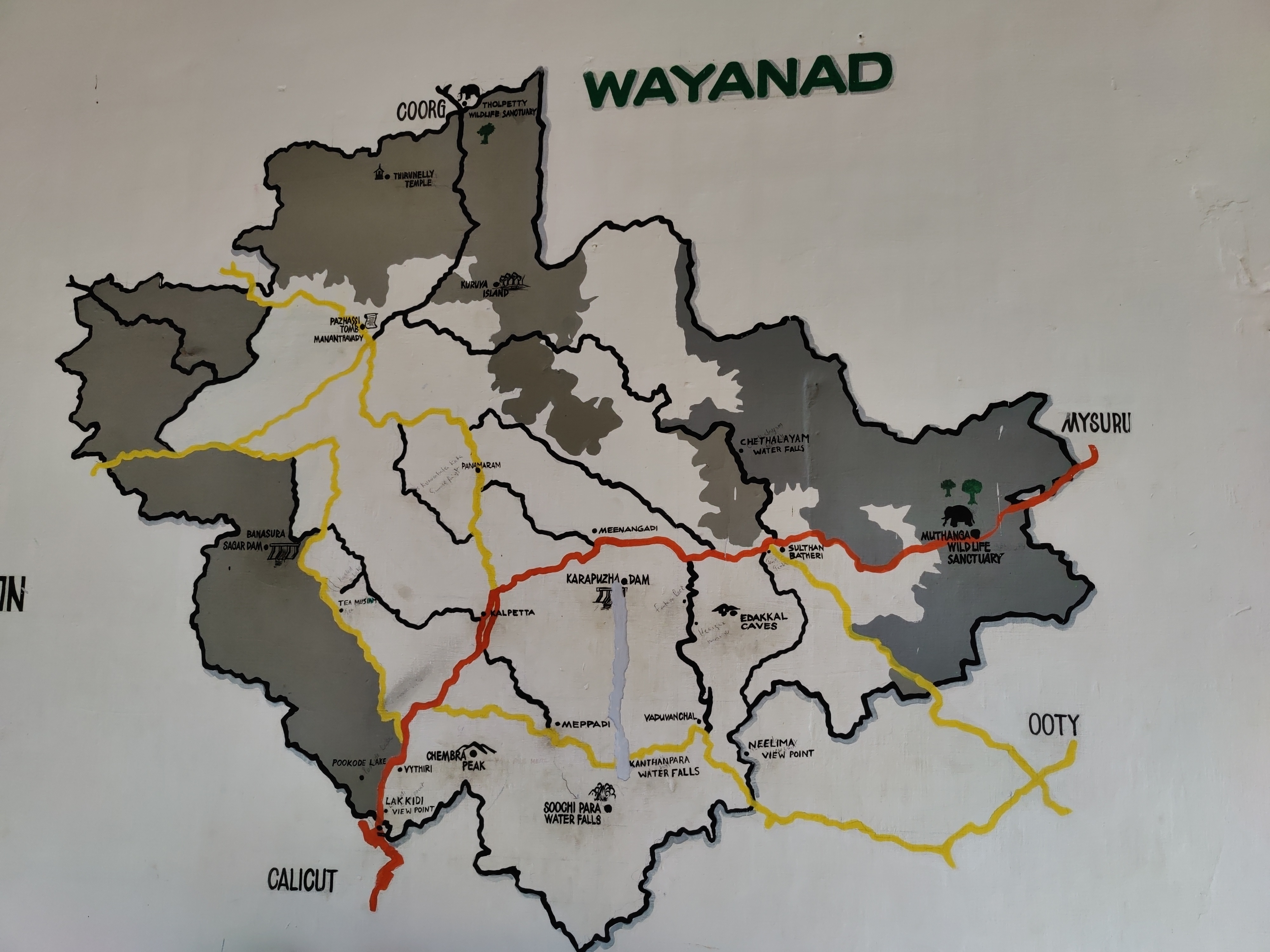 A map of Wayanad showing tourist places.
A map of Wayanad showing tourist places.
 A view from inside the Zostel Wayanad property.
A view from inside the Zostel Wayanad property.
 Terrain during trekking towards the Chembra peak.
Terrain during trekking towards the Chembra peak.
 Heart-shaped lake at the Chembra peak.
Heart-shaped lake at the Chembra peak.
 Me at the heart-shaped lake.
Me at the heart-shaped lake.
 Views from the top of the Chembra peak.
Views from the top of the Chembra peak.
 View of another peak from the heart-shaped lake.
View of another peak from the heart-shaped lake.


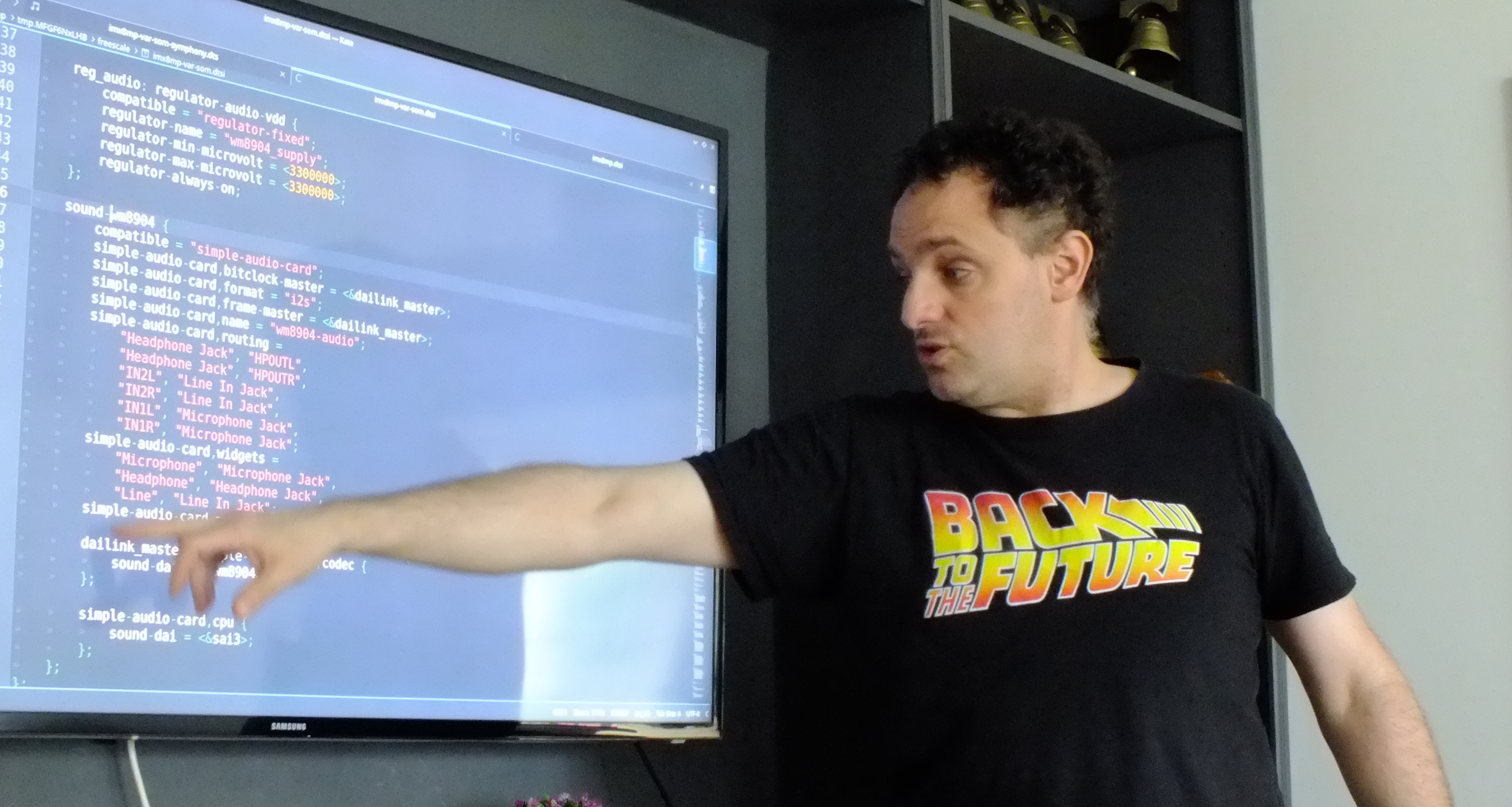
 This post describes how to handle files that are used as assets by jobs and pipelines defined on a common gitlab-ci
repository when we include those definitions from a different project.
This post describes how to handle files that are used as assets by jobs and pipelines defined on a common gitlab-ci
repository when we include those definitions from a different project.
 So This is basically a call for adoption for the Raspberry Debian images
building service. I do intend to stick around and try to help. It s not only me
(although I m responsible for the build itself) we have a nice and healthy
group of Debian people hanging out in the
So This is basically a call for adoption for the Raspberry Debian images
building service. I do intend to stick around and try to help. It s not only me
(although I m responsible for the build itself) we have a nice and healthy
group of Debian people hanging out in the  Edited 2023-08-25 01:32 BST to correct a slip.
Edited 2023-08-25 01:32 BST to correct a slip.
































 I m six months into my journey of building a business which means its time to reflect and review the goals I set for the year.
I m six months into my journey of building a business which means its time to reflect and review the goals I set for the year.